
A DataStore is an output mechanism used to generate the processed data into different file formats.
The different file types supported in Elixir Data Designer include Binary, CSV, Connection Pool, Custom Java DataStore, Excel, Google Spreadsheet, JDBC, JDBC JNDI, JSON, Text and XML.
The DataStore provides support for Command Line Invocation which allows Scheduling with any third party Scheduler such as Window Task Scheduler as well as an API for Application Integration.
If grouping is performed on a data source and the Excel DataStore is generated from it then the grouped data can be saved to multiple worksheets based on the grouping level.
The DataStore also supports XML post-processing with an XSLT transformation. An XSLT file contains a template that can transform the generated records into any textual output format.
The DataStore is selected from the menu bar of the Designer window and then placed on the diagram.
The DataStore Wizard consists of two screens. In the first screen, the name of the DataStore must be entered in the text field. The DataStore type to be generated is selected from the list in the combo box. The output fields of the data source are displayed in the DataStore Wizard.
The URL and the other settings of the file to be generated will be entered on the second screen of the DataStore Wizard. The settings on the second screen vary with each output type.
To explore the use of DataStore, connect one directly to a DataSource and generate the different outputs. A sample is shown in Figure 4.61, “Sample Datastore Flow”. Of course, usually there will be a sequence of processors that act on the records as they pass through.
Note
When trying to generate a Composite datasource with multiple Datastore processors by right-clicking on the datasource in the Repository panel and selectingGenerate, user is able to select the Datastore processor to generate.
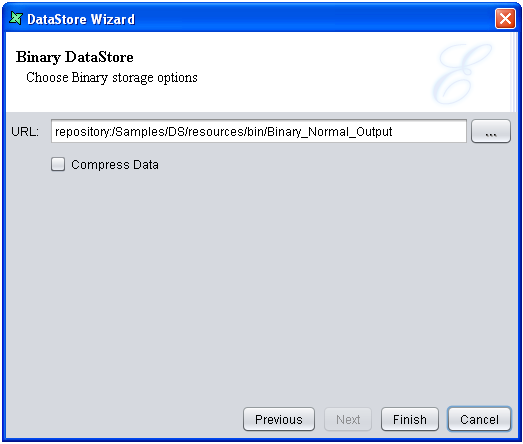
This DataStore writes data to a binary (BIN) file. Using Binary DataStore, you can generate a binary file from a Tabular DataSource, a compressed Text DataSource, an Excel DataSource, a Random DataSource, an XML DataSource or a MSSQL database. You have the option to compress the binary file, which can largely reduce the file size and consequently reduce data transfer over the network.
Open the DataStore Wizard, select the Binary type, and then click Next. The Binary DataStore window appears. Enter an appropriate URL, which indicates where the output binary file will be saved. If you want to compress the binary file, select the Compress Data check box as shown in Figure 4.62, “Binary DataStore”.
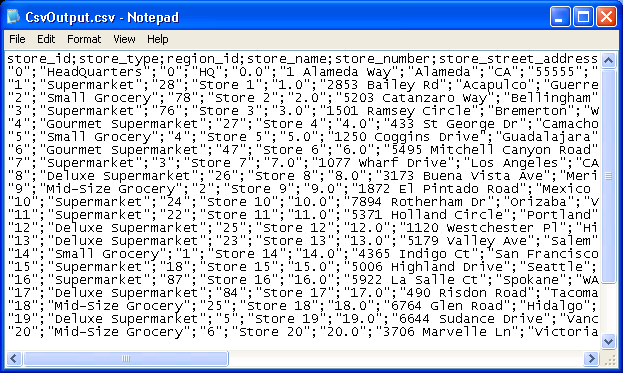
This datastore writes comma separated values to a file. Each record will be output as a single line with the fields separated by a separator character. There is no trailing separator on the end of the line. In addition, the output can wrap the output values with qualifiers. These are usually single or double quotes which ensure that values which contain the separator aren't treated as multiple fields. For example if the field value is "Hello, World" and comma is used as a separator, the CSV will be malformed, unless a qualifier is used to delimit the field.
This datastore is not suitable for fields that contain embedded newline characters. Any such values should be fixed with earlier processors before the datastore. A sample output using semi-colon separators with double-quote qualifiers is shown in Figure 4.63, “CSV Output”.
Note
- The Append Data option allows data to be appended to the end of an existing CSV file. Obviously the same separator and qualifier options (and data schema) should be retained for each addition to the file.
-
The user can enter any symbol in the
Qualifierfield instead of selecting from the drop-down list.
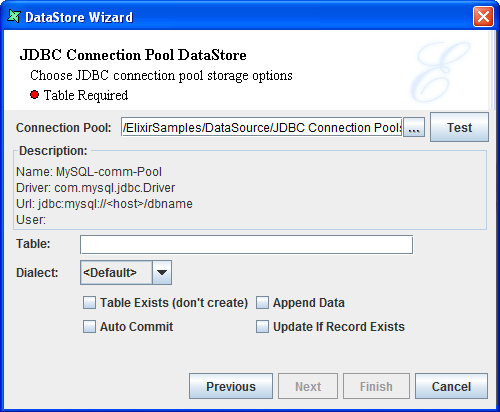
This datastore writes records to the database that the connection pool is being connected to. If a valid URL to a connection pool is selected, the description of the connection pool will be displayed, as seen in Figure 4.64, “DataStore Wizard - Connection Pool”.
Table Exists(don't create) : If this option is checked, the Table entered in the Table field will be updated accordingly. If not, a new table will be created. However, an error will occur if there is a table of the same name in the database.
Append Data : When checked, data will be updated to the specified Table accordingly.
Auto Commit : Checking this option will enable data to be updated in the database whenever changes are made. If not, new records added will not be reflected in the database.
Update If Record Exists : This option will only work if the destination table has primary key(s) defined. When checked, the system will check for the presence of record(s) based on the primary key. If found, it will perform an UPDATE. If not, it will perform an INSERT.
This option is only available to JDBC, JDBC JNDI and Connection Pool.
The Custom Java DataStore can be used to write data into any Java API, whether it be a proprietory protocol or even a mail or JMS queue. Actually, the built-in DataStore types are pre-defined instances of the Java DataStore. We can test this by using the CSV datastore as an example.
Open the DataStore Wizard and select Custom Java DataStore, then click Next. The Custom Java DataStore screen appears. Enter the class name as com.elixirtech.data2.output.CSVDataStore. The URL, append, qualifier and separator parameters appear in the table below. The CSVDataStore is written using standard JavaBean naming conventions, so the available accessors can be extracted automatically. Using CSV as an example, the DataStore screen appears as shown in fig Figure 4.65, “Custom Java Option Screen”.
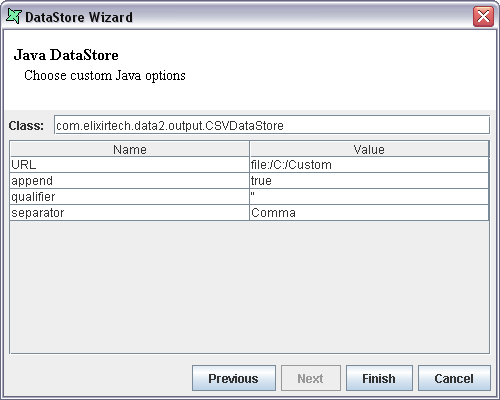
In order to implement your own DataStore you need to implement a DataListener interface. This API is described in the section called “Object DataSource API”. When you have coded and compiled your class, it should be placed in a jar in the /ext directory so that it can be loaded next time the tool is started. If you modify the jar you will need to restart Elixir Repertoire for the jar to be re-loaded. (If you are using the Remote tool, then the ext directory is on the server and you will need to restart the server). Now you can enter your class name in the Custom Java DataStore wizard and enter any values that you have exposed through get and set methods. Upon choosing Generate, your class will be invoked to process the records.
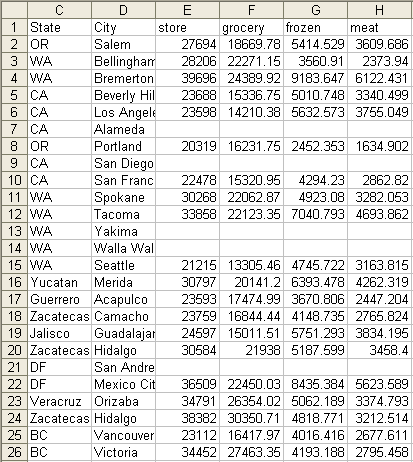
This datastore writes records to an Excel (XLS) file. By default all records will be written to a single sheet. However, if the output records are grouped, the Sheet Group Level option can be used to force subsequent data to a new sheet. For example, if there are two levels of grouping and the level value is set to 1, then each start of a new level one group will start on a separate worksheet. Each sheet will have a header, if the Column Header check box is selected. An example with column headers is shown in Figure 4.66, “Excel Output”.
Note
Different versions of Excel (and Excel compatible readers, like OpenOffice) have different limits for the maximum number of rows allowed in a single sheet. Elixir Data Designer limits the rows on one sheet to 31999.This datastore writes records to a Google Spreadsheet, from which you can access the data written for use as a Google Spreadsheet document, or work on the data for charting and other related purposes.
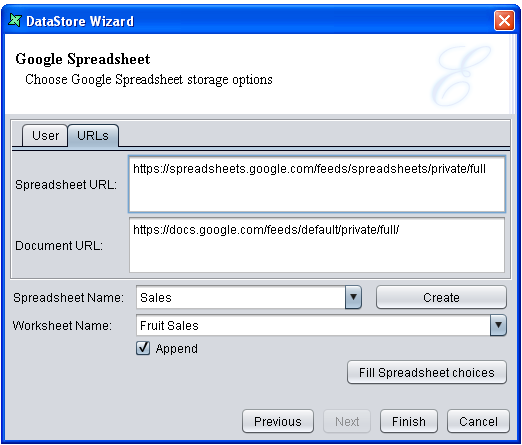
Open the DataStore Wizard, select the Google Spreadsheet type, and then click Next. The Google Spreadsheet DataStore window appears, as shown in Figure 4.67, “Google Spreadsheet DataStore - User” and Figure 4.68, “Google Spreadsheet DataStore - URLs”.
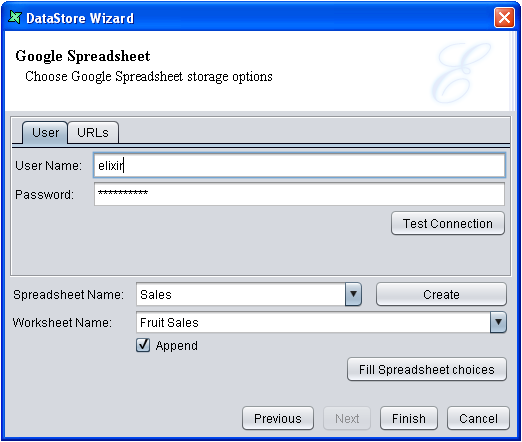
On the User tab, fill in the following fields:
User Name: Enter your Google mail account.
Password: Enter your Google mail password.
After entering the user name and password, click the
Test Connection button to verify if the connection is successful.
On the URLs tab, the following fields are automatically filled with information:
Spreadsheet URL: Leave the URL as it is.
Document URL: Leave the URL as it is.
Spreadsheet Name: If you want to load an existing spreadsheet,
click the Fill Spreadsheet choices button and choose one name from the list.
To create a new spreadsheet, enter a new spreadsheet name and click the Create button.
Worksheet Name: If you want to load an existing worksheet,
click the Fill Spreadsheet choices button and choose one name from the list.
To create a new worksheet, enter a new worksheet name after entering a new spreadsheet name and
clicking the Create button.
Append: If this check box is selected, the new records written will be appended to existing data in the spreadsheet. Otherwise, all pre-existing data will be deleted before the new records are written.
This datastore writes records to a JDBC database. The appropriate
driver and database URL need to be entered, along with a user name
and password (if required). The Table name may either by a literal table
name, like Sample, or it may be inferred from a field
in the record. If there is a field called CompanyName, with record values
of A, B, C, etc. then using ${=CompanyName} as the
table name, will put the records into tables A, B and C. Each record
could be appended to a different table.
Because table names may include spaces and other characters (particularly if they are read from field values), the datastore will wrap each string with double quotes "like this" when generating SQL codes. It may be useful to avoid this quoting if your table name also includes a schema component, for example myschema.table. This is because "myschema.table" is the name of a table in the default schema, whereas myschema.table is a table called "table" in the "myschema" schema. The latter is probably what you want, but we can't be sure. The solution is to explicitly quote the table name yourself. If quotes are already present (detected by an initial double quote mark), the datastore will not add any more. Therefore, if the table name is given as "myschema"."table" then the datastore will not introduce any extra quotes. This allows you to choose either interpretation of the table name explicitly. This discussion also applies for MySQL table names, except the back-tick (`) quote is used instead of double quotes throughout.
Note
The last page of the wizard for a JDBC datastore is for the user to specify the location to store records that failed to add, which are compiled into a datasource.This datastore writes data to a JSON (JavaScript Object Notation) file. JSON files are widely used as the input for many new charting tools, including Protovis and HighCharts. Each record will be output as a single line, in which each field name will be followed by the corresponding value with colon as the separator. Between pairs of field name and value, the separator is comma. Each record is contained in curly brackets "{}", while the entire contents are contained in square brackets "[]". The following shows a sample output of JSON DataStore:
[
{ "Company": "A", "Fruit": "Apple", "2000": 201.0, "1999": 102.0 },
{ "Company": "B", "Fruit": "Orange", "2000": 323.0, "1999": 32.0 },
{ "Company": "C", "Fruit": "Berry", "2000": 99.0, "1999": 20.0 }
]This datastore discards the records. This datastore is a useful trigger for priming data caches, or in conjunction with data drops. This is because only DataStores or Result can be triggered by name from the Elixir Runtime Engine. For example, if you want to ensure a cache is loaded, connect it to a None DataStore. Now you can generate this datastore any time you want the cache to be loaded.
This datastore writes expanded text templates to a file. By defining a template for StartData, StartGroup, ProcessRecord, EndGroup and EndData, you can control exactly how the text file is constructed. This is a flexible and fast alternative to using a Report Writer for producing text output.
A template is expanded by performing substitution of values using the familiar ${...} syntax. JavaScripts can be embedded too, by using ${=...} syntax. For example, to add the current timestamp to the output, you could use a template:
The current time is ${=java.util.Date();}The StartData template is invoked first, so this is a good place for a header. If there are any groups in the output the StartGroup and EndGroup templates will be expanded at the appropriate point. Each individual record will be expanded using ProcessRecord.
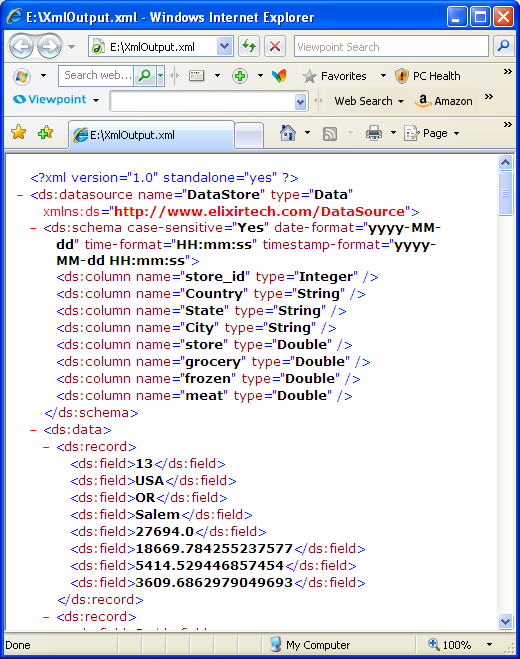
This datastore writes XML, or information transformed from XML to a file. By default, the records, along with the schema are written out in Tabular DataSource format - a simple XML structure that embeds the values directly into the data source itself, so that it has no other dependencies. You may take the XML file produced and use it with other tools, or by naming the output file with a .ds extension, you can use it as a data source. You can even write the file directly into the repository, by using a repository:/ URL so that Elixir tools can access it immediately.
By specifying the name of an XSLT transformation, the XML data output can be readily transformed into another XML structure, or any kind of text output. You could use XSLT to produce the same output as the CSV or Text DataStore, if they weren't already provided for you.
A Sample of the Tabular DataSource XML file is shown in Figure 4.69, “XML Output”.
Note
If you need to send some sample data to Elixir, generating a Tabular DataSource using the XMLDataStore is ideal, because the data source file has no dependency on your database, repository or file system configuration.