
A DataDrop is a pass-through output mechanism used to generate the data that flows through it into different file formats.
A DataDrop is closely related to a DataStore. The only difference is that a DataDrop continues to provide records to subsequent processors, whereas a DataStore is a terminal processor.
A DataDrop is particularly useful when used in conjunction with a SubFlow construct, allowing different records to flow through different paths and be saved to different files.
For more details on the features of DataDrop, review the DataStore Processor section.
To explore the use of DataDrop, connect a SubFlow between a DataSource and a DataStore as shown in Figure 4.45, “Sample DataDrop Flow”.

Then, open the SubFlow (e.g. double-click on it) and draw the flow as shown in Figure 4.46, “Sample DataDrop Sub Flow”.
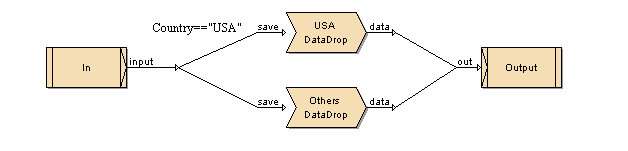
In this case, the SubFlow input splits the records into two streams. The first stream has a condition attached: Country=="USA", the other stream is left blank, so it gets all the other records. Each of these streams passes through a different DataDrop, so the records end up in one of two files. All the USA stores are now separated.
DataDrop is particularly useful for storing records that fail data cleansing or data integrity checks for subsequent processing, or for debugging complex composite diagrams.
Note
-
When trying to generate a Composite datasource with multiple Datadrop processors by
right-clicking on the datasource in the Repository panel and selecting
Generate, user is able to select the Datadrop processor to generate. -
The user can enter any symbol in the
Qualifierfield instead of selecting from the drop-down list.